I attended Strata last week (Feb 11-13) in Santa Clara, CA, a big data conference. Over the years, it has become big. This year, it can be said to become mainstream -- there are lot of novices around. I wanted to note my impressions for those who would have liked to attend the conference.
Exhibitors details
The conference exhibitors can be distributed into these groups:
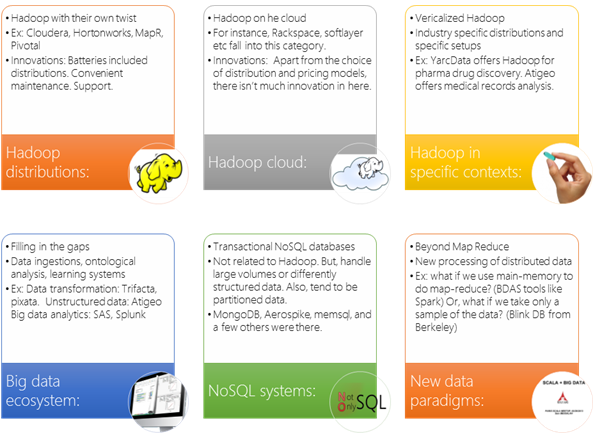
As you can see Hadoop is the big elephant in the room.
Big picture view
Most of the companies, alas, are not used to the enterprise world. They are from the valley, not the from the plains where much of these technologies can be used profitably. Even in innovation, there are only a few participants. Most of the energies are going in minute increments of usability of technology. Only a few companies are addressing the challenge of bringing Big Data to main stream companies that already invested in plethora of data technologies.
The established players like Teradata, Greenplum would like you to see big data as a standard way of operating along with their technologies. They position big data as relevant in places, and they provide mechanisms to use big data in conjunction with their technologies. They build connectors; they provide seamless access to big data from their own ecosystem.
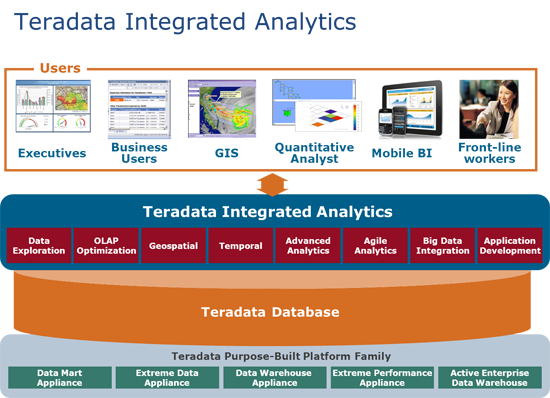
[From Teradata website.]
As you can see, Teradata’s world center is solidly its existing database product(s).
The new comers like Cloudera would like to upend the equation. They compare the data warehouse with a big DSLR camera and the big data as a Smartphone. Which gets used more? While data warehouse is perfect for some uses, it is costly, cumbersome, and doesn’t get used for most places. Instead, big data is easy, with lot of advances in the pipeline, to make it easier to use. Their view is this:
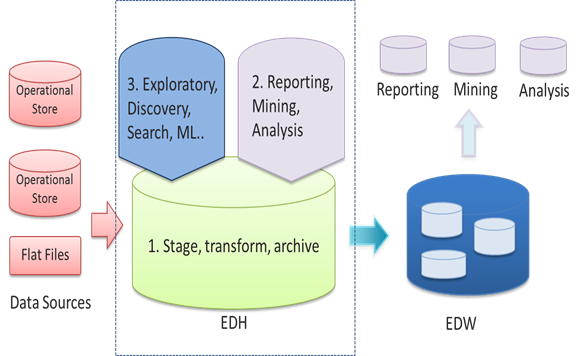
[From Cloudera presentation at Strata 2014].
Historically, in place of EDH, all you had was some sort of staging area for ETL or ELT kind of work. Now, they want to enhance it to include lot more “modern” analytics, exploratory analytics, and learning systems.
These are fundamentally different views: While both see big data systems co- existing with data warehouse, the new companies see them taking on increasing role to provide ETL, analytics, and other services. The old players see it as an augmentation to the warehouse when unstructured or large data volumes are present.
As an aside, at least Cloudera presented their vision clearly. Teradata on the other hand, came in with marketese which does not offer any information on their perspective. I had to glean through several pages to understand their positioning.
A big disappointment is Pivotal. They ceded the leadership in these matters to other companies. Considering their leadership in Java, I expected them to extend Map Reduce to multiple places. That job is taken up by Berkeley folks with Spark and other tools. With lead in Greenplum HD, I thought they would define the next generation data warehouse. They have a concept called data lake, which is merely a concept. None of the people in the booth were articulate about what it is, how it can be constructed, what way it is different, and why it is interesting.
Big data analytics and learning systems
Historically, analytics field is dominated with descriptive analytics. The initial phase of predictive analytics was focusing on getting the right kind of data (for instance, TIBCO was harping on real-time information to predict events quickly). Now that we got Big data, it is not so much as getting the right data, but computing it fast. And, not just computing fast, but having the right statistical models to evaluate correlations, causations and other statistical stuff.

[From Wikipedia on Bigdata]
These topics are very difficult for most computer programmers to grasp. Just as we needed understanding of algorithms to program in the beginning, we need the knowledge of these techniques to analyze big data these days. Just as the libraries that codified the algorithms made them accessible to any programmer (think when you had to program the data structure for an associate array), new crop of companies are creating systems to make the analytics accessible to programmers.
SQL in many bottles
A big problem with most big data systems is the not having relational structure. Big data proponents may rile against the confines of relational structures, but they are not going to fight against SQL systems. Lot of third party systems assume SQL like capabilities from the backend systems. And, lot of people are familiar with SQL systems. SQL is remarkably succinct and expressive for several natural activities on Data.
A distinct trend is to slap on SQL interface onto non-SQL data. For example presto does SQL on Big data. Or, impala does SQL on Hadoop. Pivotal does Hawq. Hortonworks does Stinger. Several of them modify SQL slightly to make it work with reasonable semantics.
Visualization
Big data conference is big on visualization. The key insight is that visualization is not something that enhances analytics or insights. It itself is a facet of analytics; it itself is an insight. Proper visualization is the key to so many other initiatives:
- Design time tools for various activities, including data transformation.
- Monitoring tools on the web
- Analytics visualization
- Interactive and exploratory analytics
The big story is D3.js. How a purely technical library like D3.js has become the de facto visualization library is something that we will revisit some other day.
Summary
I am disappointed with the state of big data. Lot of companies are chasing the technology end of the big data, with minute segmentation. The real challenges are adoption in the enterprises, where the endless details of big data and too many choices increase the complexity of solutions. These companies are not able to tell businesses why and how they should use Big data. Instead, they collude with analysts, media, and a few well-publicized cases to drum up hype.
Still, Big data is real. It will grow up. It will reduce the costs of data so dramatically to support new ways of doing old things. And, with right confluence of statistics and machine learning, we will see the fruits of big data in every industry. That is, doing new things in entirely in new ways.